
꼬물꼬물
JDBC, SQL Mapper, ORM 본문
데이터 접근 기술
프로그래밍 패러다임(객체지향) -> 데이터 저장 기술(RDBMS)
데이터 저장 기술: 데이터를 효과적으로 저장하기 위한 기술데이터 접근 기술
자바 Application <- 데이터 접근 기술(인터페이스) -> 데이터 저장 기술
DB에 접근하기
- DB Connection 얻기
- SQL 전달 및 실행: 서버에서 DB에게 원하는 동작을 SQL로 표현해 연결된 커넥션을 통해 DB에 전달
- DB Connection 닫기: DB가 전달된 SQL을 실행하고 결과 응답, 서버는 응답을 활용하고 연결된 커넥션을 닫음
🚨 데이터 접근 기술의 문제
- 각 DB마다 Connection 연결방법과 SQL 전달 방법, 응답 방법이 모두 다르다.
- DB 변경시, 서버에서 작성된 DB 코드도 변경해야 한다.
- 개발자가 각각 DB마다 커넥션 연결, SQL 전달, 결과 응답 방법을 새로 작성해야 한다.
과거
- 서비스가 작을 경우 MySQL 활용
- 사용자가 늘어 Oracle DB를 추가
- MySQL과 Oracle은 DB 접근 방식이 다르기 때문에 새로운 코드가 필요하다.
- => 데이터 접근 방법이 같다면 확장 변경이 일어나도 수정할 필요가 없을 것
JDBC 등장

- JDBC의 DataSource를 사용하면 일관된 접근 방식으로 다양한 저장 기술을 사용할 수 있다.
JDBC란? Java Database Connectivity
자바를 이용해 다양한 데이터 저장 기술에 일관적으로 접근할 수 있는 데이터 접근 기술
- DB Connection
private final DataSource dataSource;
public JdbcMemberRepository(DataSource dataSource) {
// spring을 통해 주입
this.dataSource = dataSource;
}- Statement 생성
public Member save(Member member) {
String sql = "insert into member(name) values(?)";
Connection conn = null;
PreparedStatement pstmt = null;
ResultSet rs = null; // 받는 결과
try {
conn = getConnection();
pstmt = conn.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS); // RETURN_GENERATED_KEYS: 값 반환?
pstmt.setString(1, member.getName());- 쿼리 실행
pstmt.executeUpdate(); // 실제 쿼리 날림- ResultSet 처리
rs = pstmt.getGeneratedKeys(); // RETURN_GENERATED_KEYS와 매칭되는 것. 저장한 member의 id 값을 반환한다.
if (rs.next()) { // 값이 있으면
member.setId(rs.getLong(1));
} else {
throw new SQLException("id 조회 실패");
}
return member;- 예외 처리
} catch (Exception e) {
throw new IllegalStateException(e);- Connection 닫기
} finally {
// 자원 반환해야 한다. release
close(conn, pstmt, rs);
}💡 JDBC의 한계
- 반복되는 데이터 접근 관련 코드: Conectionn, PreparedStatement, ResultSet 등의 중복
- 핵심 관심사의 미분리: CRUD와 같은 핵심 관심사, 응답을 처리하는 비핵심 관심사가 함께 있다.
- Java Code 내 SQL 직접 전달 문제
- JDBC가 사용하는 SQL은 단순 문자열로 컴파일 체크 불가능 -> 문법 오류, 오타의 발생 확률
- 자바 Application에서 SQL 언어가 핵심 로직을 담당하게 된다.
JDBC의 장단점
| 장점 | 단점 |
|---|---|
| 여러 데이터 저장 기술을 일관된 방식으로 접근 가능 | Connection, SQLException, Trasaction 등 직접적인 데이터 필요 |
| Transaction, 예외 처리 등 세부 조정 가능 | 반복적인 데이터 바인딩 |
| 반복되는 SQL 쿼리문 | |
| - 일관적 데이터 접근 | - 중복코드, 관심사 미분리 |
SQL Mapper의 등장
SQL Mapper란?
- SQL문과 객체의 필드를 매핑해 데이터를 객체화

- MyBatis, JDBCTemplate 등
Spring JDBC Template
- Statement 생성 및 바인딩
@Override
public Optional<Member> findById(Long id) {
List<Member> result = jdbcTemplate.query("SELECT * FROM MEMBER WHERE id = ?", memberRowMapper(), id);
return result.stream().findAny();
}- ResultSet 객체 매핑: RowMapper를 넘기면 알아서 객체를 반환해 준다.
private RowMapper<Member> memberRowMapper(){
return (rs, rowNum) -> {
Member member = new Member();
member.setId(rs.getLong("id"));
member.setName(rs.getString("name"));
return member;
};
}- DB Connection 열기/닫기: Spring JDBC 내부에서 실행해준다.
- SqlException try-catch
SQLException이란?
JDBC 관련 로직을 실행하는 동안 방생하는 기본 예외 클래스 SQLException
- 불필요해보이는 try-catch
- uncheckedException
- 보통 입력이 발생했을 때 SQL이 일어나게 되는데 이때 try-catch는 방법이 없다.

- Spring JDBC에서는 checkedException을 통해 불필요한 코드를 줄임
🚨 Spring JDBC의 문제점
- SQLException 해결
- Connection 관리 해결
- 트랜잭션 처리 해결
- 반복적인 데이터바인딩 미해결: 각각의 객체마다 RowMapper을 만들어줘야 한다.
- 자바코드와 쿼리문 분리 미해결
- 반복적인 SQL 쿼리문 미해결
Mybatis 등장
- XML 서술자나 어노테이션을 사용해 객체와 SQL 자동 매핑 지원
💡 Mybatis의 해결

- 자바 코드와 SQL 분리: 자바는 인터페이스에, SQL은 XML에 존재
- 반복적인 데이터 바인딩 해결: 동적 바인딩
🚨 남은 문제
- 객체지향 패러다임 불일치
- 반복적인 SQL 쿼리문
ORM
ORM이란?
- 객체와 RDB 사이의 패러다임 불일치에서 오는 불편함을 해결하기 위해 객체와 RDB를 변환시켜주는 데이터 접근 기술
- 반복적인 SQL을 직접 작성할 필요가 없으며 객체에 집중할 수 있다.
JPA(Java Persistence API)
💡 패러다임 불일치가 뭘까?


- DB

- 객체 설계
💡 1. 세분성(Granularity)
| 테이블 | 객체 |
|---|---|
| 변경이 어렵다 | 변경이 쉽다 |
| 집합적(모이는 경향) | 분해적(분리되는 경향) |
- -> 객체의 수는 테이블 수보다 빠르게 증가한다.
테이블
1. 한번 결정된 테이블을 변경하는 것은 비용 소모가 크다
2. 연관된 정보를 최대한 모아서 저장하는 경향
- application이 커질수록 테이블 수와 객체 수의 차이가 커져 관리가 어려워진다.
🚨 이에 대해 테이블에 맞춰 객체를 생성하는 데이터 중심으로 설계한다. 이는 객체지향과 멀어진다. => JPA를 사용해 객체를 데이터로 사용하자!

- 데이터 중심

- 객체 중심
💡 2. 상속 (Inheritance)

- 두 테이블을 따로 insert 해야한다.

- JPA가 각 객체에 맞춰 대신 처리해준다.
💡 3. 동일성 (Identity)
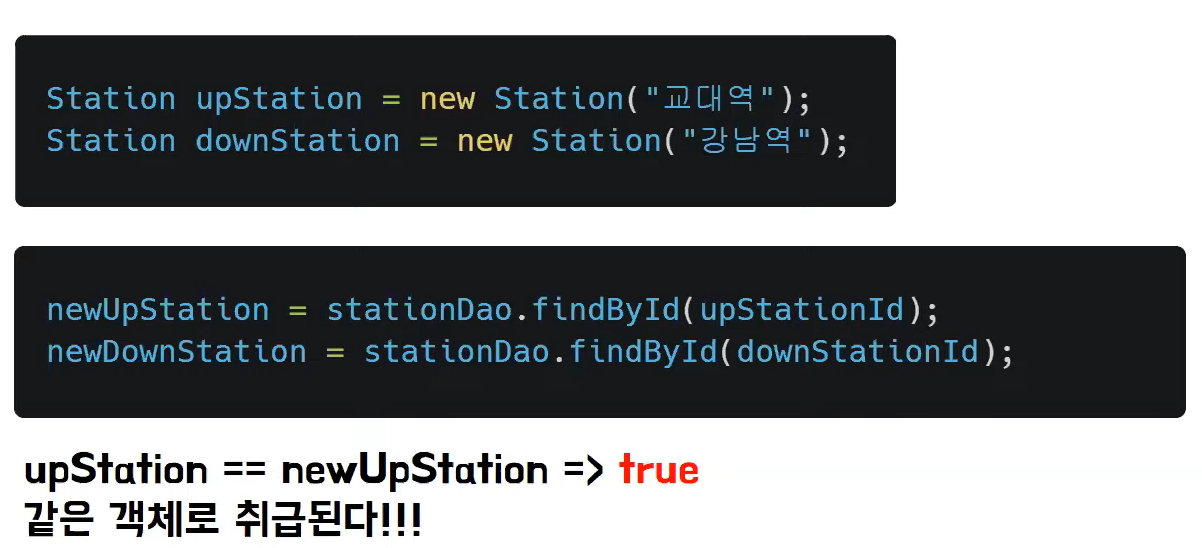
- JPA는 트랜잭션 내에서 동일한 Entity 취급을 한다
참고
'코딩 > CS' 카테고리의 다른 글
| 페이지 교체 알고리즘 (0) | 2022.11.01 |
|---|---|
| CPU 작동 원리 (0) | 2022.09.20 |
| Day2 질문 (0) | 2022.04.25 |
| HTTP/HTTPS (0) | 2022.04.25 |
| Day01 질문 (0) | 2022.04.17 |
'코딩/CS' Related Articles
more

