
꼬물꼬물
[자바의 정석]11. 컬렉션 프레임웍-1 본문
1. Collections Framework
- 데이터 군을 저장하는 클래스들을 표준화한 설계
- Java API 문서에서는 **‘데이터군을 다루고 표현하기 위한 단일화된 구조’**라고 한다.
- JDK1.2이전까지는 Vector, HashTable, Properties와 같은 컬랙션 클래스, 다수의 데이터를 저장할 수 있는 클래스를 다른 각자의 방식으로 처리했어햐 했다.
- JDK1.2부터 컬렉션 프레임웍이 등장하면서 다양한 종류의 컬렉션 클래스가 추가되고 모든 컬렉션 클래스를 표준화된 방식으로 다룰 수 있도록 체계화 됨.
- Vector와 같이 다수의 데이터를 저장할 수 있는 클래스 == 컬렉션 클래스
- 컬렉션 프레임웤은 컬렉션, 다수의 데이터를 다루는 다양한 클래스를 제공한다. 인터페이스와 다형성을 이용한 객체지향적 설계를 통해 표준화되어 있기 때문에 편리하고, 재사용성 높은 코드를 작성할 수 있다.
1.1 컬렉션 프레임웍의 핵심 인터페이스
- 컬렉션 데이터 그룹을 크게 3가지 타임이 존재한다고 인식하고 인터페이스를 만들었다.
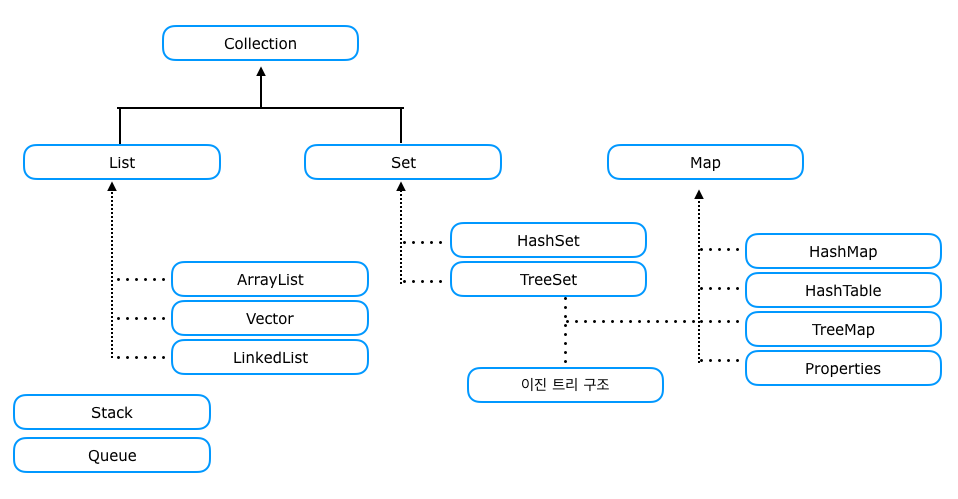
- 인터페이스 List와 Set을 구현한 컬렉션 클래스들은 서로 많은 공통부분이 있어, 공통된 부분을 뽑아 Collection인터페이스로 정의할 수 있었지만,
public interface Set<E> extends Collection<E> { ... }
public interface List<E> extends Collection<E> { ... }
public interface Map<K, V> { ... }- Map 인터페이스는 이들과 전혀 다른 형태로 컬렉션을 다루기 때문에 같은 상속계층도에 포함되지 않는다.
| 인터페이스 | 특징 |
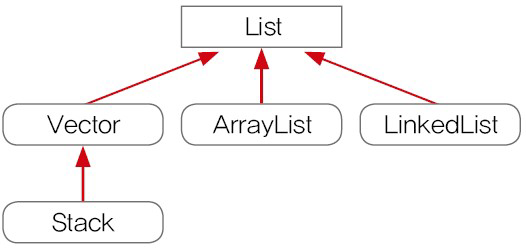
| List | - 순서가 있는 데이터 집합 - 데이터 중복 허용 구현클래스) ArrayList, LinkedList, Stack, Vector 등 |
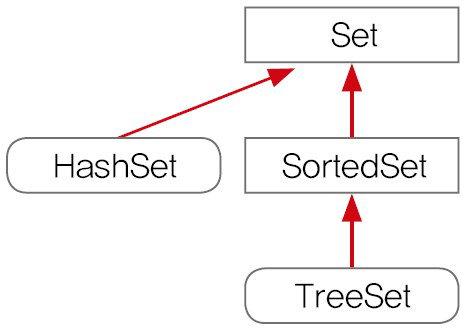
| Set | - 순서가 있는 데이터 집합 - 데이터 중복 허용 구현클래스) ArrayList, LinkedList, Stack, Vector 등 |
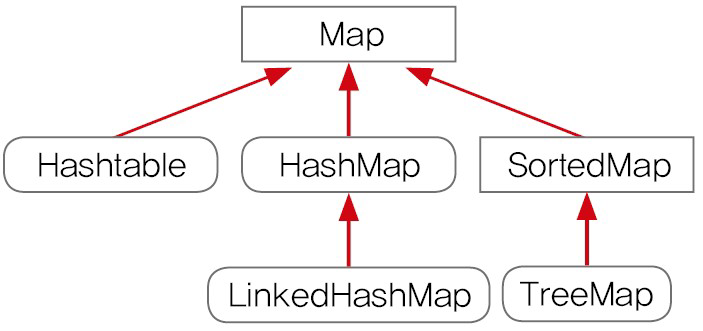
| Map | - 순서가 있는 데이터 집합 - 데이터 중복 허용 구현클래스) ArrayList, LinkedList, Stack, Vector 등 |
- 컬렉션의 특징을 파악하고 어떤 인터페이스를 구현한 컬렉션 클래스를 사용할지 결정해야한다.
- 보통 이름으로 클래스를 구분할 수 있으나, Vector, Stack, Hashtable, Properties는 컬렉션 프레임웍이 만들어지기 전부터 존재해서 이름으로 특징을 알 수 없다.
- Vector나 Hashtable과 같은 기존의 컬렉션 클래스들은 호환을 위해 남겨두었지만, 가능하면 사용하지 않는 것이 좋다.
- ArrayList와 HashMap을 사용하자.
<Collection 인터페이스>
| 메서드 | 설명 |
| boolean add(Object o) | |
| boolean addAll(Collection c) | 지정된 객체 or 컬렉션의 객체들을 추가한다. |
| void clear() | 컬렉션의 모든 객체 삭제 |
| boolean contains(Object o) | |
| boolean containsAll(Collections c) | 지정된 객체 or 컬렉션의 객체들이 컬렉션에 포함되어있는지 확인하기 |
| boolean equals(Object o) | 동일 컬렉션인지 확인한다. |
| boolean remove(Object o) | 지정된 객체를 컬렉션에서 삭제한다. |
| boolean remmoveAll(Collection c) | 지정된 Collection에 포함된 객체 삭제 |
| boolean retainAll(Collection c) | 지정된 Collection에 포함된 객체만 남기고 다른 객체를 컬렉션에서 삭제한다. Collection에 변화가 있으면 true, 없으면 false 반환 |
- 더 많은데 일단 간단하게..
- Collection 인터페이스는 컬렉션 클래스에 저장된 데이터를 읽고, 추가하고 삭제하는 등 컬렉션을 다루는데 가장 기본적인 메서드들을 정의하고 있다.
- boolean 반환값은 작업에 성공하거나 사실이면 true, 그렇지 않으면 false를 반환한다.
- Java API 문서를 보면 Object가 아닌 E로 표기되어 있는데, E(Element)는 특정 타입을 의미하는 것으로 JDK 1.5부터 추가된 제너릭스에 의한 표기.
<List 인터페이스>
- 중복 허용, 저장순서 유지
| 메서드 | 설명 |
| void add(int index, Object element) boolean addAll(int indexm Collection c) |
지정된 위치(index)에 객체 또는 컬렉션에 포함된 객체를 추가한다. |
| Object get(int index) | 지정된 위치에 있는 객체 반환 |
| int indexOf(Object o) | 지정된 객체의 위치를 반환 (첫번째 요소부터 순방향으로 찾는다) |
| int lastIndexOf(Object o) | 지정된 객체의 뤼치를 반환 (마지막 요소부터 역방향으로 찾는다) |
| Object remove(int index) | 지정된 위치에 있는 객체를 삭제하고, 삭제된 객체 반환 |
| Object set(int index, Object element) | 지정된 위치에 객체를 저장한다. |
| void sort(Comparator c) | 지정된 비교자로 List 정렬 |
| List subList(int fromIdx, int toIdx) | 지정된 번위에 있는 객체를 반환. (fronIdx부터 toIdx전까지) |
<Set 인터페이스>
- 중복 비허용, 저장순서 비유지
<Map 인터페이스>
- key(키)와 value(값)을 하나의 쌍으로 묶어 저장.
- 키는 중복 비허용, 값은 중복 허용
- 기존에 저장된 데이터와 중복된 키를 저장하면 기존 값은 없어지고 마지막에 저장된 값이 남는다.
| 메서드 | 설명 |
| void clear() | Map의 모든 객체 삭제 |
| boolean containsKey(Object key) | 지정된 key 객체와 일치하는 Map의 key가 있는지 확인 |
| boolean containsValue(Object value) | 지정된 value 객체와 일치하는 Map의 value객첵 있는지 확인 |
| Set entrySet() | Map에 저장되어 있는 key-value 쌍을 Map.Entry 타입의 객체로 저장한 Set으로 반 |
| boolean equals(Object o) | 동일한 Map인지 비교 |
| Object get(Object key) | 지정한 key에 대응하는 value객체를 반환 |
| int hashCode() | 해시코드 반환 |
| Set keySet() | Map에 저장된 모든 key객체를 반환한다. |
| Object put(Object key, Object value) | Map에 value객체를 key객체와 연결해(mapping) 저장한다. |
| void putAll(Map t) | 지정된 Map의 모든 key-value 쌍을 추가한다. |
| Object remove(Object key) | 지정한 key객체와 일치하는 key-value객체를 삭제한다. |
| Collection values() | Map에 저장된 모든 value객체 반환 |
- values()에서는 반환타입이 Collection이고, keySet()에서는 반환타입이 Set이다.
- Map인터페이스에서 값(value)은 중복 허용이기 때문에, Collection 타입으로,
- 키(key)는 중복 비허용이므로 Set 타입으로 반환한다.
<Map.Entry 인터페이스>
interface Entry<K, V> { ... }
- Map 인터페이스의 내부 인터페이스(inner interface)
- Map에 저장되는 key-value 쌍을 다루기 위해 내부적으로 Entry 인터페이스를 정의해 놓았다.
- 보다 객체지향적으로 설계하도록 유도하기 위해 Map을 구현하는 인터페이스에서는 Map.Entry 인터페이스도 함께 구현해야 한다.
1.2 ArrayList
- List 인터페이스를 구현하기 때문에 데이터의 저장 순서가 유지되고 중복이 허용된다.
- ArrayList는 기존의 Vector를 개선한 것.
- Object 배열을 이용해 데이터를 순차적으로 저장한다. 배열에 저장할 공간이 없다면 보다 큰 새로운 배열을 생성해 복사한 다음 저장한다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData; // object 배열
}
- elementData라는 이름의 Object 배열을 멤버변수로 선언한다.
- 최고 조상인 Object이므로 모든 종류의 객체를 담을 수 있다.
| 메서드 | 설명 |
| ArrayList() | 크기가 10인 ArrayList 생성 |
| ArrayList(Collection c) | 주어진 컬렉션이 저장된 ArrayList 생성 |
| ArrayList(int initialCapacity) | 지정된 초기용량을 갖는 ArrayList 생성 |
| boolean add(Object o) | 마지막 객체 추가. 성공하면 true |
| void add(int idx, Object o) | 지정된 위치에 객체 저장 |
| boolean addAll(Colection) | 컬렉션의 모든 객체 저장 |
| boolean addAll(int idx, Collection c) | 지정된 위치부터 주어진 컬렉션의 모든 객체를 저장한다. |
| Object clone() | ArrayList를 복사한다. cloneable을 상속받고 있음 |
| boolean contains(Object o) | 지정된 객체의 ArrayList 포함 여부 |
| Object remove(int idx) | 지정된 위치에 있는 객체 삭제 |
| boolean remove(Object o) | 지정한 객체 삭제 |
| boolean removeAll(Collection c) | 지정한 컬렉션에 저장된 것과 동일한 객체를 ArrayList에서 제거한다. |
| boolean retainAll(Collection c) | ArrayList에 저장된 객체 중 주어진 컬렉션과 공통된 것만 남기고 나머지는 삭제한다. |
| Object[] toArray() | ArrayList에 저장된 모든 객체를 객체배열로 담아 반환 |
| void trimToSize() | 용량을 크기에 맞게 줄인다. |
Collection은 인터페이스과 Collections는 클래스
<trimToSize>
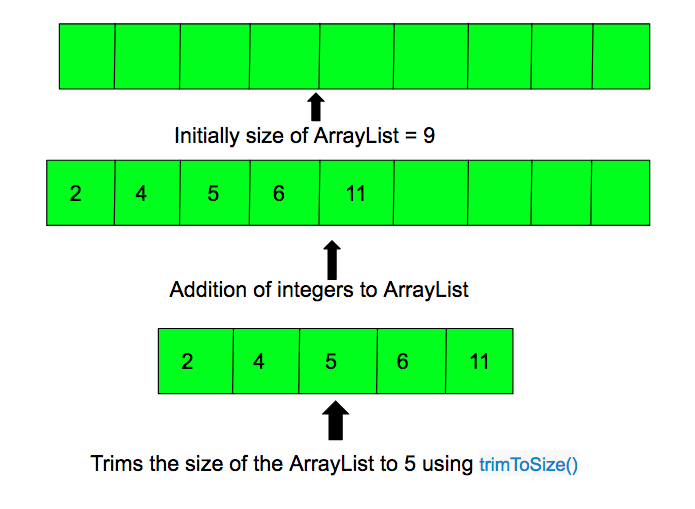
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
?EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
- 선언한 실제 용량보다 크기가 작다면 용량을 크기와 맞춘다.
- 전혀 새로운 배열이 만들어지므로 기존의 인스턴스는 GC에 의해 삭제된다.
- ArrayList나 Vector 같이 배열을 이용한 자료구조는 데이터를 읽어오고 저장하는 데는 효율이 좋지만,
- 용량을 변경해야할 때는 새로운 배열을 생성한 후, 기존의 배열로 부터 새로 생성된 배열로 데이터를 복사해야하기 때문에 효율이 떨어진다.
- 그래서 처음 인스턴스 생성시, 용량을 고려해 생성하는 것이 좋다.
<System.arraycopy()>
public static native void arraycopy(Object src, int srcPos, Object dest, int destPos,int length);
- System.arraycopy(data, 3, data, 2, 2);
- data[3]부터 2개의 길이를 data[2]부터 2개의 길이에 복사
- 순차적으로 지울 때는 호출하지 않지만, 중간에 위치한 객체를 추가하거나 삭제하는 경우 System.arraycopy를 호출해야 하기 때문에, 작업시간이 오래걸린다.
1.3 LinkedList

- 배열은 가장 기본적인 형태의 자료구조로 구조가 간단하며 사용하기 쉽고 데이터를 읽어오는데 걸리는 시간(접근 시간)이 빠르다는 장점이 있지만
- 단점으로는
- 크기를 변경할 수 없다.
- 새로운 배열을 생성해 데이터를 복사해야한다.
- 실행속도 향상을 위해서는 충분히 큰 크기의 배열을 생성해야해서 메모리 낭비
- 비순차적인 데이터의 추가/삭제에 시간이 오래 걸린다.
- 차례대로 데이터를 추가하고 마지막부터 삭제하는 것은 빠르지만,
- 배열의 중간에 데이터를 추가하려면 빈자리를 만들기 위해 다른 데이터들을 복사해서 이용해야한다.
- 크기를 변경할 수 없다.
<단순 링크드 리스트>
- 이러한 배열의 단점을 보완하기 위해 LinkedList 자료구조가 등장했다.
- 배열은 모든 데이터가 연속적으로 존재하지만 링크드 리스트는 불연속적으로 존재하는 데이터를 서로 연결한 형태로 구성된다.
class Node {
Node next; // 다음 요소의 주소를 저장
Object obj; // 데이터를 저장
}
- LinkedList의 각 요소(Node)들은 자신과 연결된 다음 요소에 대한 참조(주소값)와 데이터로 구성되어 있다.
- 데이터 삭제가 간단하다.
- 삭제하고자 하는 요소의 이전 요소가 삭제하고자하는 요소의 다음 요소를 참조하도록 변경하기만 하면 된다.
- 배열처럼 데이터를 이동하기 위해 복사하는 과정이 없어 처리속도가 매우 빠르다.
- 데이터 추가
- 새로운 요소를 생성한 다음, 추가하고자 하는 위치의 이전 요소의 참조를 새로운 요소에 대한 참조로 변경하고,
- 새로운 요소가 그 다음 요소를 참조하도록 변경하기만 하면 된다. 또한 처리속도가 빠르다.
- 링크드 리스트는 이동 방향이 단방향이기 때문에 다음 요소에 대한 접근은 귑지만 이전 요소에 대한 접근이 어렵다.
- 이를 보완한 것이 더블 링크드 리스트(doubly linked list)
<더블 링크드 리스트>
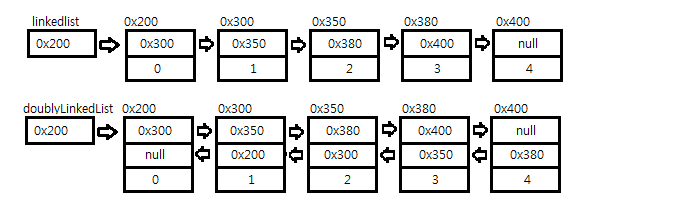
class Node {
Node next; // 다음 요소의 주소를 저장
Node previous; // 이전 요소의 주소를 저장
Object obj; // 데이터를 저장
}
- 단순 링크드 리스트에 참조변수를 하나 더 추가해 다음 요소에 대한 참조뿐만 아니라 이전 요소에 대한 참조가 가능하게 한다.
<더블 써큘러 링크드 리스트(이중 원형 연결리스)>
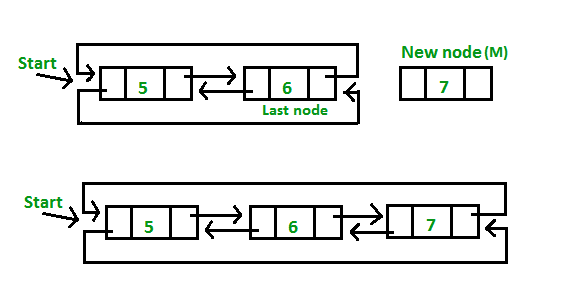
- 맨 처음 노드의 이전 노트가 맨 마지막 노드가 된다.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
...
private static class Node<E> {
E item; // 값
Node<E> next; // 다음 요소의 주소
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
...
}
- 실제 LinkedList는 Doubly Linked List(더블 연결리스트)로 구현되어 있다.
| ArrayList | LinkedList | |
| 순차적 추가 | 빠름 | 느림 |
| 중간에 추가 | 느림 | 빠름 |
| 중간에 삭제 | 느림 | 빠름 |
| 순차적 삭제 | 빠름 | 느림 |
- 순차적인 경우 ArrayList가 빠르다.
- 추가하는 경우 ArrayList의 크기가 작다면 LinkedList가 빠를 수도 있다.
- 삭제의 경우 크기는 변하지 않는다. 그냥 안의 요소값이 null이 될 뿐
- 중간 데이터를 추가/삭제하는 경우 LinkedList가 빠르다.
- LinkedList의 경우, 각 요소간의 연결만 변경해주면 되기 때문에 처리속도가 매우 빠르다.
- ArrayList는 각 요소들을 재배치하여 추가할 공간을 확보하거나 빈 공간을 채워야해 처리속도가 느리다.
- 데이터의 개수가 그리 크지 않으면 어느 것을 사용해도 큰 차이가 나지 않는다.
<접근 시간>
- 배열(ArrayList)의 경우, 인덱스가 n인 요소의 값을 얻고자 한다면, 단순히
- 인덱스가 n인 데이터 주소 = 배열의 주소 + n * 데이터 타입의 크기
- 로 빠르게 접근 가능하다.
- 배열은 각 요소들이 연속적으로 메모리상에 존재하기 때문이다.
- LinkedList의 경우, 불연속적으로 위치한 각 요소들이 서로 연결된 것이라 처음부터 n번째 데이터까지 차례대로 따라가야 한다.
- 데이터의 개수가 많아질수록 접근시간이 길어진다.
| 접근시간(읽기) | 추가/삭제 | ||
| ArrayList | 빠름 | 느림 | - 순차적인 추가/삭제는 빠르다. - 비효율적인 메모리 사용 |
| LinkedList | 느림 | 빠름 | - 데이터가 많을 수록 접근성이 떨어진다. |
- 비효율적인 메모리 사용 | | LinkedList | 느림 | 빠름 | - 데이터가 많을 수록 접근성이 떨어진다. |
- 다루고자하는 데이터의 개수가 변하지 않는 경우라면 ArrayList
- 데이터 개수의 변경이 잦다면 LinkedList
- 데이터 저장에는 ArrayList를 작업할때는 LinkedList를 사용할 수도 있다.
- 컬렉션끼리 변환이 가능한 생성자를 제공하고 있다.
1.4 Stack과 Queue
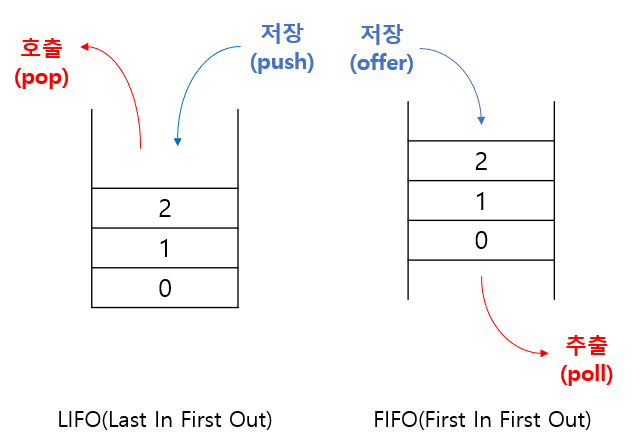
- 스택은 마지막에 저장한 데이터를 가장 먼저 꺼내는 LIFO 구조
- 큐는 처음 저장한 데이터를 가장 먼저 꺼내는 FIFO 구조
💡 Stack과 Queue를 구현하기 위해선 어떤 컬렉션 클래스를 사용하는게 좋을까?
- 순차적으로 데이터를 추가하고 삭제하는 스택에는 ArrayList와 같은 배열기반의 클래스가 적합하지만,
- 큐는 데이터를 꺼낼 때, 항상 첫 번째 저장된 데이터를 삭제하므로 ArrayList를 사용하면 데이터를 꺼낼 때마다 데이터의 복사가 발생해 비효율적이다.
- 그래서 큐는 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
Stack<Integer> stack = new Stack<>();
Queue<Integer> queue = new LinkedList<>();Stack은 구현체 클래스가 존재하지만 Queue는 인터페이스로만 정의해놓아 구현체를 골라 사용할 수 있다.
큐의 구현체
<스택과 큐의 활용>
- Stack
- 수식계산, 수식괄호검사, 웹브라우저의 뒤로/앞으로
- Queue
- 최근 사용 문서, 인쇄작업 대기목록, 버퍼
<PriorityQueue>
- Queue 인터페이스의 구현체 중 하나로, 저장한 순서에 관계없이 우선순위(priority)가 높은 것부터 꺼내게 된다.
- 가장 우선순위가 높은 값을 가져온다.
- null은 저장할 수 없다. NullPointerException 발생
- PriorityQueue는 저장공간으로 배열을 사용하며, 각 요소를 **힙(heap)**이라는 자료구조의 형태로 저장한다.
- 힙은 이진트리의 한 종류로 가장 큰 값이나 작은 값을 빠르게 찾을 수 있다는 특징을 갖는다.
<Deque(Double-Ended Queue)>
- Queue의 변형으로, 한쪽 끝으로만 추가/삭제할 수 있는 Queue와 달리, Deque(덱)은 양쪽 끝에 추가/삭제가 가능하다.
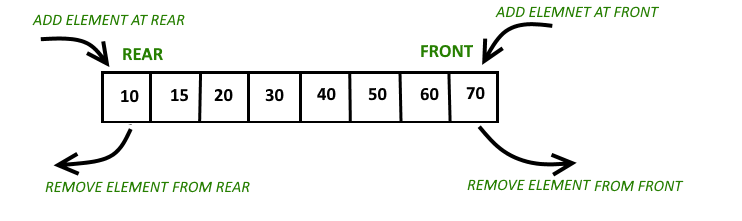
1.5 Iterator, ListIterator, Enumeration
- 모두 컬렉션에 저장된 요소를 접근하는데 사용되는 인터페이스이다.
- Enumeration은 Iterator의 구버전이며, ListIterator는 Iterator의 기능을 향상시킨 것
<Iterator>
- 컬렉션 프레임웍은 컬렉션에 저장된 요소를 읽어오는 방법을 표준화했다.
- 컬렉션에 저장된 각 요소에 접근하는 기능을 가진 Iterator 인터페이스를 정의하고 Collection 인터페이스에서는 Iterator(구현한 클래스의 인스턴)를 반환하는 iterator()를 정의한다.
public interface Collection<E> extends Iterable<E> {
...
Iterator<E> iterator();
...
}
public interface Iterator<E> {
boolean hasNext();
Object next();
void remove();
}
- iterator()는 Collection 인터페이스에 정의된 메서드로 Collection 인터페이스의 자손인 List와 Set에도 포함되어 있다.
- List와 Set을 구현하는 컬렉션은 iterator()가 특징에 맞게 작성되어있다.
- 컬렉션 클래스에 대해 iterator()를 호출해 Iterator을 얻은 다음 반복문을 사용해 각 클래스의 요소를 읽어온다.
| 메서드 | 설명 |
| boolean hasNext() | - 읽어올 요소가 남아있는지 확인 - 있으면 true, 없으면 false |
| Object next() | - 다음 요소를 읽어온다. next() 호출 전, hasNext를 호출해 읽어올 요소가 있는지 확인하기 |
| void remove() | - 다음 요소를 읽어온다. next() 호출 전, hasNext를 호출해 읽어올 요소가 있는지 확인하기 |
💡 참조변수의 타입은 인터페이스로 사용하자.
구현체에만 있는 메서드를 사용하는 것이 아니라면, 인터페이스로 참조변수를 선언하는 것이 좋다. 아래 코드가 전부 해당 인터페이스안에 있는 것만 사용하고 있다고 확신할 수 있기 때문에, 후에 구현체 변경에도 편하다.
<Map의 iterator()>
- Map 인터페이스를 구현한 컬렉션 클래스는 key와 value를 쌍으로 저장하기 때무에 iterator()를 직접 호출할 수 없다
- 대신 keySet()이나 entrySet()을 사용해 키와 값을 각각 따로 Set의 형태로 받아 다시 iterator()를 호출해야 Iterator를 얻을 수 있다.
<ListIterator와 Enumeration>
- Enumeration은 컬렉션 프레임웍이 만들어지기 이전에 사용하던 것
- ListInterator는 Iterator를 상속받아 기능을 추가한 것으로, 컬렉션의 요소에 접근할 때, Iterator는 단방향으로 이동할 수 있는데 반해 ListIterator는 양방향으로의 이동이 가능하다.
- 다만, ArrayList나 LinkedList와 같이 List인터페이스를 구현한 컬렉션에만 사용할 수 있다.
1.6 Arrays
- Arrays 클래스에는 배열을 다루는데 유용한 메서드가 정의되어 있다.
- 같은 기능의 메서드가 배열의 타입만 다르게 오버로딩되어 있다.
- Arrays에 정의된 메서드는 모두 static 메서드이다.
<배열의 복사 - copyOf(), copyOfRange()>
- copyOf()는 배열 전체를, copyOfRange()는 배열의 일부를 복사해 새로운 배열을 만들어 반환한다.
- range의 경우 마지막은 포함되지 않는다. copyOfRage(arr, 1, 3); // 1,2
- copyOf(복사할 arr, 복사할 길이)가 복사할 arr보다 복사할 길이가 크다면, 기본값으로 채워진다.
- 예)
- Arrays.copyOf(arr, arr.length);
- Arrays.copyOfRange(arr, 1, 3);
<배열 채우기 - fill(), setAll()>
- fill()은 배열의 모든 요소를 지정된 값으로 채운다.
- setAll()은 배열을 채우는데 사용할 함수형 인터페이스를 매개변수로 받는다.
- 예)
- Arrays.fill(arr, 9);
- Arrays.setAll(arr, () → (int) (Math.random() * 5) + 1); // 람다식
- 예)
<배열의 정렬과 검색 - sort(), binarySearch()>
- sort()는 배열을 정렬할 때
- binarySearch()는 배열에 저장된 요소를 검색할 때 사용한다.
- binarySearch()는 배열에서 지정된 값이 저장된 위치(idx)를 찾아 반환하는데, 이때 반드시 배열이 정렬되어야 올바른 결과를 얻는다.
- 여러개 일치하는 경우, 어떤 것이 올지는 모른다.
- 예)
- Arrays.binarySearch(arr, 2); // 2가 있는 index를 반환한다.
- 순차 검색의 경우, 배열이 정렬되어 있을 필요는 없지만, 배열의 요소를 하나씩 비교하기 때문에 시간이 오래 걸림
- 반면 이진 검색은 배열의 검색 범위를 반복적으로 절반씩 줄어가며 검색하기 때문에 검색속도가 매우 빠르다.
- 단, 배열이 정렬되어 있는 경우만 사용할 수 있다는 단점이 있다.
<배열의 비교와 출력 - equals(), toString()>
- toString()은 배열의 모든 요소를 문자열로 현하게 출력할 수 있다.
- 일차원 배열에만 사용할 수 있으므로 다차원 배열에는 deepToString을 사용해야 한다.
- 배열의 모든 요소를 재귀적으로 접근해 문자열을 구성해 2,3차원 가능
- equals()는 두 배열에 저장된 모든 요소를 비교해 같으면 true, 다르면 false
- 일차원 배열에만 사용할 수 있으므로 다차원 배열 비교에는 deepEquals()를 사용한다.
<배열을 List로 변환 - asList(Object … a)>
- asList()는 배열을 List에 담아 반환한다.
- 매개변수의 타입이 가변인수라 배열 생성없이 저장할 요소만 나열하는 것도 가능하다.
- 🚨 asList()가 반환한 List의 크기는 변경할 수 없다.
- 추가/삭제가 불가능하다.
- 저장된 내용은 변경가능하다.
- 크기를 변경할 수 있는 List가 필요하다면?
- List list = new ArrayList(Arrays.asList(1,2,3,4,5));
<parallelXXX(), spliterator(), steam()>
- parallel로 시작하는 메서드들은 보다 빠른 결과를 얻기 위해 여러 쓰레드가 작업을 나누어 처리한다.
- spliterator()는 여러 스레드가 처리할 수 있게 하나의 작업을 여러 작업으로 나누는 Spliterator를 반환한다.
- stream()은 컬렉션을 스트림으로 변환한다.
'스터디 > JAVA' 카테고리의 다른 글
| LinkedList (0) | 2024.07.07 |
|---|---|
| [자바의 정석]11. 컬렉션 프레임웍-2 (1) | 2022.10.29 |
| 다우기술 문제풀이 회고 (0) | 2022.10.26 |
| [자바의 정석] Generics(제너릭스) (0) | 2022.10.25 |
| [자바의 정석] java.lang패키지와 유용한 클래스 (0) | 2022.10.14 |
'스터디/JAVA' Related Articles
more
